Figure 1 – Lawrence Fishburn holding a Duracell-like C size battery in the Matrix, prior to moving on to portraying homeless city martial arts gang leader, turned urban pigeon farmer, in the John Wick franchise. Duracell obviously didn’t sponsor the movie and therefore the Wachowski’s were being careful to avoid licensing and trademark infringement issues.
Disclaimer: If you already know this stuff, just click here and move on to something more challenging or interesting. This is for people unfamiliar with Progressive Web Apps, or PWA’s, which essentially turn a web page into a shortcut that opens in a separate “app window” of sorts.
I’m using ChatGPT and Google Bard for examples only. You can do this pretty much with ANY web site. In my humblest of humbled humble opinions, PWA’s are best for VERY simple UI web sites, such as single form layouts, like the main Google search page. Busier layouts tend to get over-crowded in the windowed-frame of a PWA, but that’s just my backwoods, corn-fed, raised-by-wolves, back alley, semi-educated, oh-shit-the-toaster-is-burning, opinion. Feel free to disregard.
The experience of creating a PWA shortcut is a little different in each browser. It’s worth noting that PWA shortcuts aren’t really “portable”, so don’t expect much if you try to copy the shortcuts to another machine. You need to recreate them on other machines.
I will demonstrate, while standing on one leg, with both eyes closed, and a small poodle, hanging by his teeth from my left butt cheek, how to do this in Google Chrome, Microsoft Edge, Brave browser, and Mozilla Firefox.
If you use another browser, like Safari, you’re probably not even reading this right now, or if you use Opera, Vivaldi, or whatever, I don’t know. Individuality died decades ago. We’re all supposed to dress, eat, talk, and act alike now. Let’s move on…
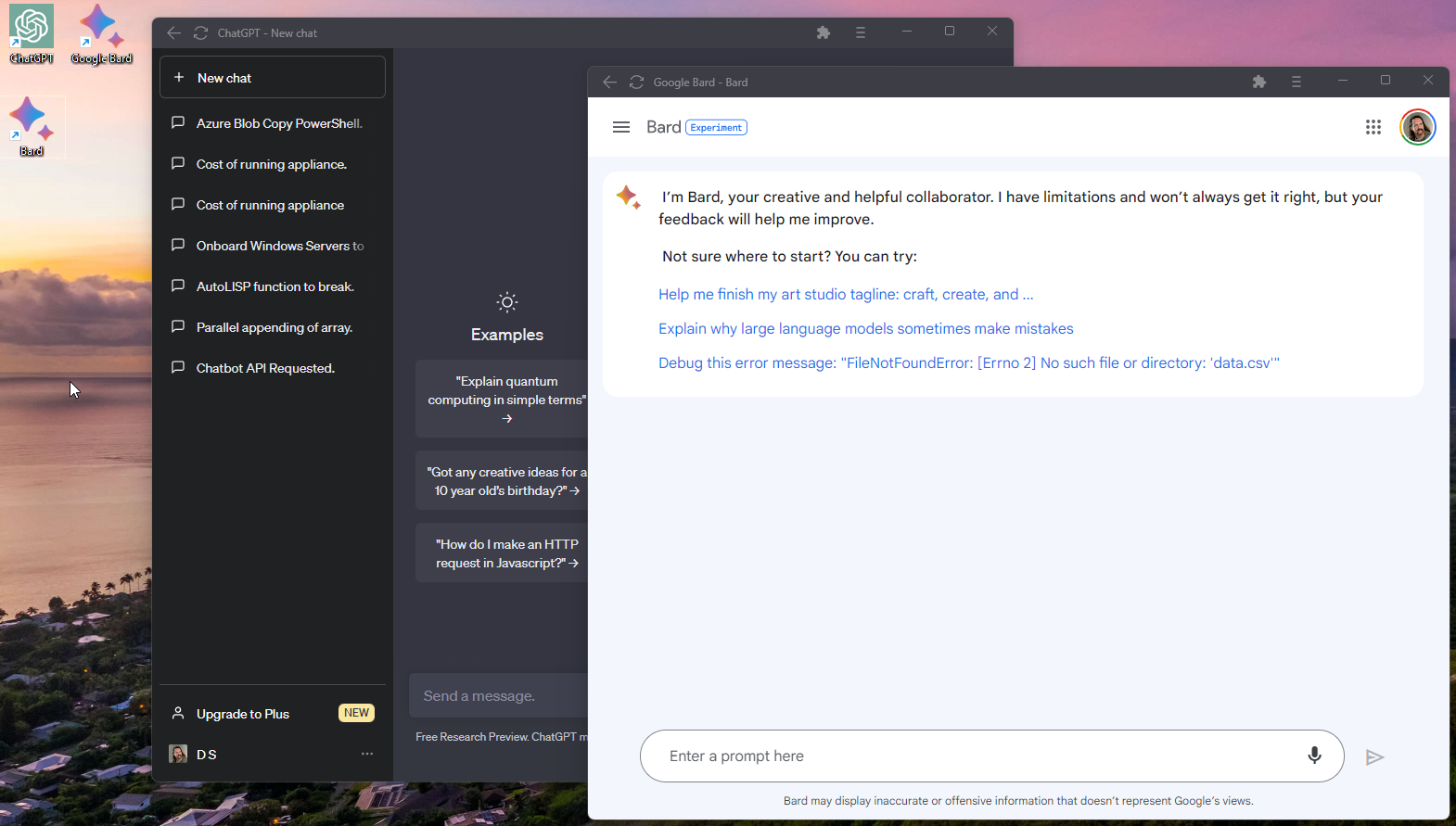
Figure 2 – ChatGPT (background) and Bard (foreground) PWA forms, along with their desktop shortcuts at upper left.
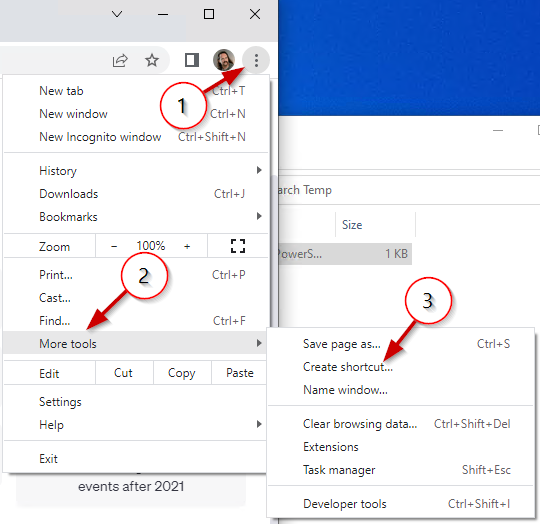
Google Chrome
Click the options menu (ellipsis “…” at top right)
Click “More tools >”
Click “Create shortcut…”
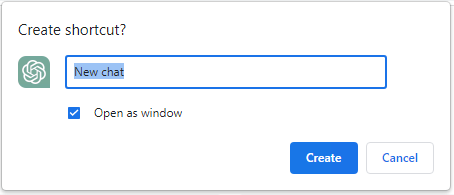
Accept or edit the name, and check “Open as window”
Click “Create”
Figure 3 – cheap graphics produced with Greenshot.
Figure 4 – more cheap graphics.
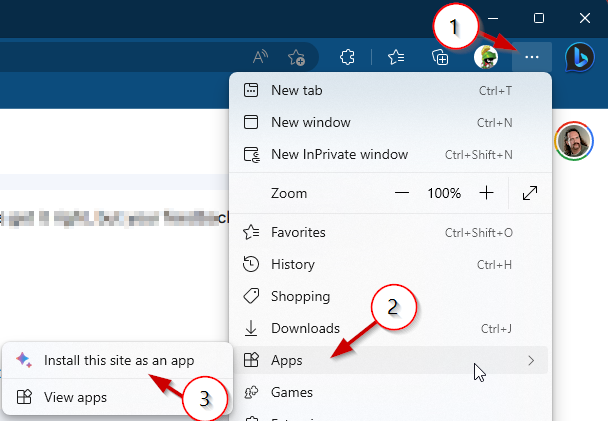
Microsoft Edge
Click the options menu (ellipsis “…” at top right)
Click “Apps”
Click “Install this site as an app”
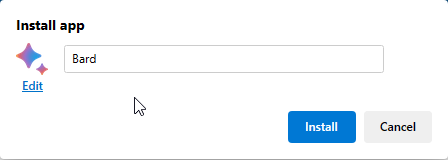
Accept the name (or edit it). Click “Edit” to assign a custom icon if you wish
Click “Install”
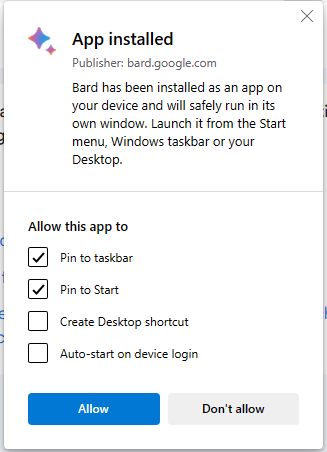
After the App is created, it will open and display another options menu
Check the options you prefer:
Pin to taskbar
Pin to Start
Create Desktop shortcut
Auto-start on device login
Click “Allow” or “Don’t allow”
Figure 5 – even more cheap graphics.
Figure 6 – you guessed it.
Figure 7 – even cheaper graphics.
Brave
The process for creating a PWA with Brave browser is exactly the same as with Google Chrome. That’s because Brave is built on the same Chrome engine, but removes all the Google tracking bullshit and adds wonderful tracking and script blockers.
Mozilla Firefox
Firefox doesn’t do PWA’s yet. I just wanted to see if you read this far.
Conclusion
PWA’s can be handy for some web sites and for some uses, but like all technology stuff, it comes down to personal preference. If you haven’t tried them, I would suggest giving them a try and see for yourself if they’re helpful. Then you can throw the term around at your next party and impress all your friends.
I’m glad you stopped by! I’ll try to write something useful again soon. We’ll see.
As I mentioned near the end of my previous post, this is actually my 4th blog endeavor. My first blog, “the Code Mine” was dedicated to AutoCAD customization (from R10 to 2004, roughly). It lived sometime between 2000 and 2004. Then I started a (VB) script-oriented blog named Scriptzilla, and it burned down, fell over and sank into the swamp.
In 2007, the first open-ended “Skatterbrainz” blog grew from a random discussion during a stressful job change, and listening to Jeff Beck’s “Scatterbrain”, but it was built on Blogger. After seven years of Google ignoring Blogger, I moved it over to WordPress in 2014. So this iteration is 9 years old. But the “Skatterbrainz” blog, as a concept, is now 16 years old. My blogging hallucinations are now roughly 23 years old.
And with that, it’s time to try something else. Thank you for following along with me on this narrated story of life! Enjoy some of these images from the past 16 years of blogging. So long and thanks for the fish!
but I won’t blame you if you bail out before the end. I hope you don’t.
I felt it was appropriate that I take this moment to offer respects to not only one of the most prolific musicians in the past 50 years, incredible guitarist, writer, producer, and who helped launch many other musicians into their careers along the way… but the person for whom I borrowed my online nickname. More on that later…
He was performing most of his life, up until very recently. Early on he would use a pick, like you can see here on She’s a Woman, but he switched very soon to pure bare-fingered playing the rest of his career. You might assume/expect I’m a guitar-player. Nope! I appreciate guitar. And other instruments (just not cowbell much). I was a “professional” drummer from 1981 to 1990, meaning I earned enough from playing local gigs to put gas in my little truck, buy food, clothes, drum sticks, and drum heads.
Jeff Beck was a busy guy indeed. He just finished a track with Ozzy Osbourne in the last year (it’s 2023 now) called “Patient Number 9”. He passed away this week at 78 years old.
The musicians who’ve worked with him was staggering. Just Google “Jeff Beck band members“
When Van Halen 1984 was released, I heard “Hot for Teacher” the first time. I had been listening to There and Back, and the song “Space Boogie” in which Simon Phillips uses a similar shuffle-beat on the double-bass, but it has an odd meter. Trying to learn that song, helped me try to learn Hot for Teacher [sort of] enough to fool drunk audience members at the dives our band played that Summer. I never nailed either song, but it was fun struggling to get closer.
“She’s a Woman” BBC live recording. (I apologize if that offends anyone, given this is 2023, but that’s the actual title), I think from 1975 (I was 11 years old). One of the rare times he played with either a pick or a talk-box (remember Peter Frampton or Richie Sambora?).
“Sling Shot”. From the Arsenio Hall show. December 4, 1989. Terry Bozzio on drums, Tony Hymas on keyboards. If you need another example of Terry during the infamous Zappa days, check out this performance on City of Tiny Lights or playing The Black Page with ZPZ (the most difficult percussion piece ever written?)
“Elegy for Dunkirk” Royal Albert Hall, 2010. With Olivia Safe on vocals.
“This is a Song for Hedy Lamarr” recorded in 2022 with Johnny Depp (yes, that Johnny Depp) on vocals.
“Nessun Dorna” from Emotion & Commotion (2010).
“What God Wants, Part 1” (2015) on Roger Waters’ tune. Jeff was 70 years old when this was recorded! Think about that next time someone says they’re “old”.
“Cause We’ve Ended As Lovers“. Live at Ronnie Scott’s in LA, November 2007. Tal Wilkenfeld on bass. Vinnie Colaiuta on drums (another Zappa alumnist). Tal was 21 years old on this recording.
Star Cycle. From the album “There and Back”. Live in 2017. With Jan Hammer on keyboards, Jonathan Joseph on drums, Carmen Vandenberg on rhythm guitar, Rhonda Smith on bass. Did you notice a theme yet? Jeff would often showcase awesome female musicians, like Jennifer Batten, Mary Hart, Tal Wilkenfeld, Mohini Dey, Rhonda Smith,
“Mna Na Heirann” 2013, with Tal Wilkenfeld on bass, Lizzie Ball on violin. I didn’t catch the names of the drummer or keyboardist.
…and so many more. The Pump (you might recognize it from the movie Risky Business), Never Alone, Star Cycle, Beck’s Bolero, Nadia, Grease Monkey, Hot Rod Honeymoon, Where Were You?, Big Block, Pork Pie Hat, THX 1138, Declan, Hammerhead, and one of my favorites to crank up loud: Pork-U-Pine.
I was in the midst of a “challenging” acquisition/divestiture/implosion at a company after 7 years. I began the blog sitting in my back yard, on a brick-of-a-laptop, and needed a name. I was jamming to Jeff Beck, and the song Scatterbrain started playing. I thought “I’m scatter-brained! Why not?!” and it was so.
Scatterbrain, live in Japan, 2006
This is actually my 4th blog. My first, “the Code Mine” was dedicated to AutoCAD customization (from R10 to R14 and 2000). Then I started a (VB) script-oriented blog named Scriptzilla. Then my first open-ended “Skatterbrainz” blog on Blogger, from 2007 to 2014. After Google let Blogger dry up, I moved to WordPress in 2014. So this iteration is 9 years old. But the “Skatterbrainz” blog is now 16 years old.
Yeah. I guess you could say I was fan. Rest in peace.
And with that, it’s time to sign off. Thank you for reading! Enjoy!…(you can listen to this last one loud or quiet)…
2022 has been an interesting turn away from the trajectory of the previous two years. Some things seem to be almost “normal” (aka, pre -2020 standards of behavior), while others are still just starting to diverge. Diverge from what? Glad you asked!
The divergence from the psychological toilet flush on our social demeanor. Two years of angry and hurtful spewage of us/them bullshit in almost every corner: politics, religion, gender, race, food, drink, sports, transportation, kids/family, neighbors, climate, international stuff, you name it. Every single area of conversation could easily turn into an all-out soldering-iron-face-stabbing incident, with video coverage on every social media platform possible.
Personally, the best things to happen to me in 2022 (in no particular order):
Recovering from COVID and Pneumonia (tough to spell that)
Learning new things (technology, house repair, medical, nutrition, health, etc.)
Whatever happens with Twitter, I have very much enjoyed the honor of getting to meet and interact with so many people I would otherwise not likely have met in real life. The amount of knowledge I gained, and new perspectives I absorbed, the craziness, all of it, I wouldn’t trade it for all the Facebooks and Tik Toks of the world. Mastodon (skatterbrainz@infosec.exchange) is a new frontier for me, but it’s too soon for me to know if it will replace Twitter for my stupid rants and thoughts. We shall see what 2023 brings.
Alas, nothing in technology is forever (okay, except for old scripts). Bulletin boards, CompuServe and Prodigy, AOL (yuck!), GeoCities, MySpace, YouTube, Facebook, Twitter, G+, on and on and on. Someday these platforms of today will be old and forgotten. Hard to imagine it now, but it will happen. It has to. It’s the way life works: the old gives way to the new.
Azure Automation Consternation Gyration over Procrastination Constipation
I love Azure Automation. I really do. Just in general. I know it’s not as sexy and fit as PowerApps or Functions, but it feels more like my dog. Always happy to see me. Never argues about my opinions or what I want in life. It just wags its tail and brings me a warm plate of fresh baked automation tools. I don’t use all of it, but most of it. But for what I need it does the job just fine.
That said…
I was recently informed by trusted sources that Microsoft had seriously entertained thoughts of using the D word on it, unilaterally. The D word of course being “deprecate”. And by “unilateral”, of course, I’m referring to their time-tested, age-proven track record of gathering customer feedback before making big changes. I mean, just look at Windows 11. Every single customer wanted that new Start Menu and Task bar, right? Obviously the masses spoke up and they just reacted. Silly me.
Any-who, I’m glad they put the gun down and stepped back from the ledge on that one. Because, I, and so many others I know, depend HEAVILY on that platform to drive CRITICAL and CORE operations for an incredibly diverse set of needs. You may not personally ever touch that product/service/platform (I really don’t know what the appropriate term is, but who cares), but trust me (as you trust everything on the Internet) it is a vital part of many environments around the globe.
So, how do you quantify “vital”? I doubt telemetry can be applied, since frequency and volume do not equate to importance. If you disagree, using the standard axiom test theorem: If you counted text messages to your boss or coworkers, and compared that count with your family members, does that mean your family is less important? And yes, “standard axiom theorem” is something I just made up, but that’s beside the point.
What remains for the future of Azure Automation? Is it truly on a roadmap of some kind? Is that roadmap being drawn by shareholders? Or is it drawn by program managers, who “know best” what we need? Who knows. I’ve submitted feedback, but it seems to go to the same place my complaints about crappy music end up.
Here’s my 2023 wish-list of improvements. Assuming this platform/service/product really has a future:
Provide UI drop-downs for [ValidateSet()] lists like [boolean] works
Provide UI support for [ValidateRange()] and [ValidateNotNullOrEmpty()] (stop+warn before running)
Add a new asset category for “Files” (e.g. JSON, XML, YAML)
Allow for encrypting File assets like that for variables
Add a new service/license tier for runbooks start time SLA of “less than 10 minutes” or “doesn’t suck” (current SLA is supposedly 30 minutes)
Clone the Test Panel sidebar UI into the main published UI (so I don’t have to re-enter everything for each subsequent Run)
Move the “Description” panel into the “Overview” panel (combine them)
The main “Jobs” panel should include a “Find Job” search feature like the one tied to each Runbook
Bonus Crazy Idea: Integrate the Publish process with GitHub or ADO to provide change history and approval capabilities
Am I asking too much? Don’t answer that. I want to pretend it matters.
Other Azure Gripes
Azure VM “Run Command” should allow add/editing/saving powershell statements like saving queries in Log Analytics
Azure VM Defender alerts for risky Run Command operations should include the statement that was entered/executed, so you can, you know, review what happened
Azure AD activity log should actually show what changed when someone modifies the “UsageLocation” property of users
Try / Catch / Finally
Finally, I just wanted to wish you and your family, friends, coworkers, neighbors, classmates, dogs, cats, fish, birds, and reptiles, a nice Thanksgiving, and a very happy (and safe) Holidays through the rest of 2022! May you find happiness and positivity and share it with others.
Welcome! And thank you for being here today. This is a momentus point in the esteemed history of Microsoft. 2069 will be an important year along the timeline of our incredible journey, and even though I’ve been dead for several years, I humbly accepted the offer to assume the role of CEO of Microsoft from Satya III. As I embark on my new tenure, I would like to announce the following changes, effectively immediately:
Lunch rooms on campus will serve only ice cream, tacos and Adderall
The naming department within the branding division will be eliminated. Employees of that department are hereby reassigned to maintain my new fleet of margarita machines.
To cover the ever-increasing costs of my margarita machines, toilets in all campus buildings will remain free to enter, but will require credit, Apple-Pay or G-Pay to exit, maybe Venmo
Software update defects will be assigned to a root cause, most likely Jimmy. Jimmy’s pay will be deducted 10% for each confirmed monthly patch defect.
One team will be assigned the responsibility of establishing and enforcing UX standardization across all products and platforms. Any deviations to the UX standard must be submitted to the “UX Standards Deviation Rejection” department.
Windows 42 will finally eliminate “Program Files”, “Program Files (x64)” and “Program Files (x86)” folders in lieu of the new “Apps” folder
Apps which still use .exe installers will be required to install under the new \ShittyApps folder
The rolling balls progress indicator is hereby replaced with swinging balls
All product versioning/branding will match the major/minor versioning. Violations will result in public humiliation and uncomfortable treatment. For example, Windows 42 will be version 42.0.0.0, rather than 10.29000.0.0.
All conferences will now serve only high-fiber foods and super-caffeinated drinks, combined with our new pay-toilets.
I’ll think of more for my next round of changes.
Send any questions to Jimmy
SCOM Monitor Script for Memory Spikes – 2 Variations
I was going to reference the old U.S. Pork industry advertising slogan for a tiny little joke here, but nobody under 50 would likely remember it. Anyhow, it was basically, “the other white meat“, and was going to be aimed at the Log Analytics replacement/extension aspect. But today, that might be mistaken as a reference to some politician or news anchor.
Anyhow, these snippets were from a recent client engagement (that’s sort of like a mini-project, not a marriage agreement), where the client wanted to gather some memory spike information with a little aggregation. And by aggregation, I mean that they wanted to sample multiple times in a short window and get an average, rather than a single sample. I don’t have enough bourbon to dive into a deep Stephen Hawking-ish explanation, but in short, it’s what the client wanted, so that’s what I did. Or do. I did do. Do be do be doo. ok.
Variation 1 – the SPAM and potatoes dinner version
Just check how that memory rump roast is doing in the oven, once per polling cycle.
$os = Get-WmiObject -Class Win32_OperatingSystem
$memory = ((($os.TotalVisibleMemorySize - $os.FreePhysicalMemory) / $os.TotalVisibleMemorySize)) * 100
$memory = [math]::Round($memory,0)
#Write-Host $avg # uncomment for debug/test only
$api = $null
$api = New-Object -ComObject "MOM.ScriptAPI"
$bag = $api.CreatePropertyBag()
$bag.AddValue("Percent", $memory)
$bag
#$api.Return($bag) # for testing only, not within scom or ps-ise
Variation 2 – the SPAM, potatoes and sugary desert-thingy dinner version
The Windows Update feature provided an option to include PowerShell modules and packages?
All applications were required to support a silent, command-line install, or be labeled as evil?
Access was separated from the Office suite?
Windows 11 shipped with PowerShell 7.x (latest version) installed?
Windows 11 shipped with the latest PowerShellGet installed?
Every PowerShell cmdlet that returned multiple objects supported -Filter?
Test-Path actually worked with -Credential?
Finding an Azure AD Device
Okay, smarty-pants. Yes, I know you’re pointing at your laptop right now and grinning “it’s right here!”. I’m talking about the digital representation of your device, which exists in Azure AD.
You might think this is as simple as Get-AzureADDevice -SearchString “DESKTOP1234”, which it may be. But you’ve been alive long enough to know nothing is ever that easy, especially in the real world. Sometimes, a given Azure AD device will appear as both “registered” and hybrid-joined. Same name, different ID and property set. In most cases both will be enabled, but only one of them is valid, and that one will have an ApproximateLastLogonTimestamp property with a data assigned.
For this wonderful scenario, you can use the -Filter parameter to isolate the device which is really active.
Scene: Smoldering battle scene within a contemporary urban conflict. Remnants of buildings surrounded by piles of fallen debris. Wild dogs scatter about. Rats diving into murky drain covers. Soldiers crouched behind a damaged brick wall, trying to avoid incoming rounds. Occasional puffs of dust and sand, as bullets ricochet off the tattered brick walls. One of the soldiers stands up to move, gets hit with a bullet, and falls. A few teammates encircle to apply first aid…
Soldier 1, “Where did it hit you?“
Soldier 2, “I think it’s my back. Left side.” (coughing) “Is it bad? I’m feeling cold. (coughing)”
Soldier 5, “Is he going to be okay?“
Soldier 1, “It’s ‘they’, Bobby. This isn’t the time to be disrespectful, okay?“
Soldier 5, “I’m sorry. I’m sorry. Is, umm, are, ‘they’ going to be okay?“
Soldier 1, “He’ll be fine. Hand me the kit.“
Soldier 3, “You smell that?” (looking at soldier 1)
Soldier 1, “Wait…” he looks confused, pauses the gauss wrap, then he and soldier 3 look at each other.
Soldier 2, “That smells like…” (coughing)
Soldier 3, “…Pumpkin spice!“
Soldier 2, “Am I going make it!?! I want to see my wife and…” (coughing, then passes out)
Soldier 5, “That must be those new pumpkin spice bullets! According to CENTCOM, they’re available only for a limited time, while supplies last.“
Soldier 1, “Amazing!”
Soldier 3, “No kidding. I wonder what other flavors they’ll be making” (another soldier takes a hit and falls)
Soldier 4, “Central-intel says cinnamon spice, peppermint, and new Elderberry, are also out“
Terrorists across the town square, “We have Elderberry also!“
Soldier 2, “Elderberry?!” (lets out his last breath and dies)
Soldier 1, “Elderberry contains antioxidants and supposedly provides soothing benefits.“
Another soldier takes a round and falls.
Soldier 5, “That was Apple Cinnamon.“
Soldier 4, “Roger that. These claims have not been approved by the FDA. Consult your doctor before taking“
Soldier 6, (takes a hit and is knocked back a few feet and falls down)
Soldier 7, “Wow! Eggnog!“
Narrator reads off list of potential side effects and warnings, while simultaneously showing slow-motion video of soldiers playing and laughing. Back to your sports analysis show, already in progress…
Whoever invented the first argument over what’s the “best programming language”, probably in some office kitchen somewhere.
ImportExcel to the Rescue, again
What can I say? I love Doug Finke‘s PowerShell module ImportExcel. It’s the bee’s knees. It’s the beer to my pizza. The socks to my shoes. The, well, you get the idea. I posted an example for using it to do a search/replace on a column of values in an Excel workbook way way back in 2021 (MCMLCXVIIIVXII in tech years). Then a reader posted a comment asking about how to search an entire worksheet, which actually isn’t that difficult to do…
$filepath = "<path-to-your-amazing-workbook-file-with-the-xlsx-extension>"
$worksheet = "Projects" # tab name
$oldstring = "Accounting" # string to search for
$newstring = "Finance" # string to replace it with
try {
if (-not(Test-Path $filepath)) {throw "file not found: $filepath"}
$xldata = Import-Excel -Path $filepath -WorksheetName $worksheet -ErrorAction Stop
$columns = $xldata[0].psobject.Properties.Name
foreach ($row in $xldata) {
foreach ($cell in $columns) {
$oldvalue = $row."$cell"
$newvalue = $oldvalue -replace $oldstring, $newstring
$row."$cell" = $newvalue
}
}
$xldata | Export-Excel -Path $filepath -WorksheetName "Links" -ClearSheet -Show
}
catch {
Write-Error $_.Exception.Message
Write-Warning "oh no?! we suck again!"
}
Then I realized you could easily extend this to search through all worksheets in a workbook. First, fetch the worksheet names then wrap the existing foreach() in another foreach(), like a Joe Pesci inside an enigma. I went ahead and poured some formatting sauce on it, and sprinkled cmdletbinding() dust to finish it off, and let it bake for 45 minutes.
If you signed an agreement with a consulting company, and start scheduling meetings, there are some additional things to consider. When you join a conference call (Teams, Zoom, Webex, etc.) and see multiple people on the call from the consulting company, make sure you understand why. The same is true for participants from your organization.
Having too many people on a conference call can add distraction, slow down progress of discussion, and may expose sensitive information to people who don’t really need to know. In addition, anyone who joined, but isn’t contributing to the discussion or being provided information relevant to their role, is likely billing for time on your account.
It’s worth clarifying who each person is, and what role(s) they’re covering. In addition, verify their need to be on the current conference call. Just because they joined the call doesn’t mean they have any active participation in the topic of discussion. If you’re unsure, at least ask if they’re billing to your account for that time.
It’s a good idea to discuss this with the PM on the consulting side, and make sure they’re careful to invite only the people necessary for the proposed discussion topic. Some PM’s will include billing guidance in their meeting invites, which helps not only the consultants, but the customer (you) understand what’s being billed against.
Then again, if your budget isn’t a concern, no worries.
My Recent Apple Support Experience
Earlier this week, I received an email to my personal inbox saying that my Apple ID password had been reset. I traded my last iPhone for an Android phone back around 2008 or 2009, as best as I can recall, so this was a bit of a surprise.
I double-checked the email, and it was legit, so I went to the Apple ID web site using the “I forgot my password” link, and successfully changed my password. It then sent another confirmation, and suggested I change my security questions next. This is where the fun began (if “fun” means having your body thrown to a pool of crocodiles)
The secret questions were in either Chinese or Korean, so I couldn’t understand them, or change them. So I changed the password, and tested it successfully. Then a few minutes later, another email, and the password was changed by the hackers. I repeated the process, but realized it’s a waste of time. So, I reached out to Apple.
Apple Support remained on the phone with me as I explained what happened, and they had me walk through the usual checklist of things I had already tried. Then they “escalated” me to a “senior support engineer” in the “Apple ID division”, according to technician number 1 (Aaron). I didn’t get the name of the senior person, but they basically said, “yeah, it sucks. There’s nothing Apple can do. But you can submit a feedback request to improve this experience”
I asked if they can at least disable or lock the account since it has been hacked. “Not possible” is what I was told. So, if you don’t have MFA enabled on your AppleID account (my account predated MFA), and someone hacks your account and changes your security questions, you are ****ed.
Be careful out there
The blogging will slow down for a while, as I adjust to some recent life changes. For one, my oldest daughter just had her second baby, which makes me grandpa (or “papa”) version 3.0 now. Second oldest daughter is remodeling her house to get ready to move. Third daughter is about to move home from overseas after 4 years away. Son is about to lose his mind over third daughter trying to boss him around from far away, and he’s on tour doing what he loves (playing music).
With Summer (technically) here, I will be spending more time on house repair projects, so I’ll be tweeting things like smashing my fingers and toes with heavy tools, or commenting on random strange people mumbling to themselves while comparing toilet seats in the Home Depot. I may still pop up and blog sometime, who knows.
This is a long one (or long-winded) so I hope you don’t have plans to do anything exciting for a while. It’s been a crazy week, so there may be some typos in this. Enjoy!
MMS MOA 2022
So much happened at the Midwest Management Summit (MMS) at Mall of America, in just a few days that it’s hard for me to condense it all into a single blog post. Several people (or more?) have their shared their own MMSMOA experiences on social media or on their blogs, and I encourage you to read all of them.
My experience began with leaving at 6:30 AM for a 4-hour plane trip, getting to the hotel around 11 AM (time zone shifted) and wobbling up to the front desk. Hotel check-in was at 3 PM, so I stashed my luggage, and was about to find some sort of lunch, but my plans immediately changed. As soon as I turned around, I was forced to join the brewery tour, sponsored by 2-pint. Okay, I wasn’t really forced. But having only slept a few hours, having no breakfast or lunch, my brain was running on auto-pilot (not that one, the other one).
The brewery tour buses were packed with interesting folks from all over the planet. The bus I stumbled onto was filled mostly with folks from Sweden, Belgium, Denmark, Russia, Scotland and ‘Merica. At least, that’s all I can recall. One of the Swede’s was having a great time doing his own Karaoke thing in the back, which was amazing. And I was trying to have an intelligent conversation with other intelligent people, even though I didn’t remotely qualify as intelligent at that time. It was really fun!
Special, extra-double thanks to the 2-Pint Software team for sponsoring that expedition. I got to talk with so many awesome people, or tried to, since the music was pretty loud, and the bus driver was straight out of GTA. That bus must have had some awesome shock absorbers.
After we finished up at Wabasha brewery, we headed over to Bad Weather Brewing, and somehow made it back to the hotel only 5 minutes after the speaker meet-up began. I don’t remember much of the rest of Sunday. But got a good night’s sleep.
50,000 foot Level (15240 meters for you foreign folks)
The session topics covered a lot of areas, which you can see here. The speakers should be well-known to anyone working with Microsoft products and/or managing devices and applications. The attendees, like many of the speakers, came from almost every imaginable industry or education environment.
Some of the focus areas included Intune Proactive Remediations, WUfB, Autopilot, Always-On VPN deployments with Intune, LAPS (and Cloud LAPS), OSCloud, WimWitch, patch automation, Patch My PC, network traffic and content delivery optimization, customizing task sequences, driver management, application packaging and deployment, and more.
Day 1 – Monday
Jeff Scripter and I co-presented on PowerShell Debugging techniques. Actually, he drove, and I tried to keep up. The meetings he and I had leading up to that day were really helpful for me, and I learned a lot from him on things I didn’t know about debugging, runspaces, and more. Later that day I sat in on a “Nerds of a Feather” session with Scott Corio and Donnie Taylor on PowerShell.
Day 2 – Tuesday
I don’t recall much of Tuesday. It was a blur. Going from session to session and trying to soak up a firehose of information. One of the after-parties was that evening.
Day 3 – Wednesday
I co-presented with Nathan Ziehnert on Automating ConfigMgr Health Checks. Most of that session went according to plan, except for one PowerShell function crash and me trying to sing-and-dance around it. The front row had quite a few plaid jackets which wasn’t humbling to see, but nobody threw tomatoes, so I consider it a success.
Both sessions received positive feedback, so I’ll take that as a good reaction. If you haven’t submitted your feedback yet, please do so, and please be brutally honest. You paid for these sessions, and we rely on your feedback to know if we delivered value in return. Thank you!
The rest of Day 3 was kind of a post-adrenaline depletion blur, but I think there was an after-party that day. I went to one sponsored by Patch My PC, and another sponsored by Recast Software. Both events were fantastic! The mix of food, drinks, games, conversation and laughter was well worth the trip alone.
Day 4 – Thursday
I had a few more things like a “camping session” with John Marcum and Richard Hicks. Two guys I’ve always wanted to meet and I’m glad it finally happened. I also finally got to meet Wally Mead, whom I’d not met before.
Later that day I was asked to do another “Birds of a Feather” session on PowerShell, by myself, which was fun. It was a small group, and we had a great discussion on building modules. Apparently I was a last-minute fill-in and a “real” MVP person came to take that over, but it was still a fun meeting.
Different Angles
For me it felt like there were two distinct experiences at the conference, as a speaker/presenter, and as an attendee. I need to break this into two perspectives:
On the speaker side of things: I had the honor of presenting with Jeff Scripter (yes, I know, he has the best surname on earth) on debugging PowerShell, and another session with Nathan Ziehnert on ConfigMgr health checks.
I had a great time in both of these and came away with some lessons learned as well. One of those being that I have a long way to go learning how to be a good speaker. Some are born with an innate talent for that, and others, like me, are not. But I’m always happy to learn.
From the attendee side: I finally got to meet so many people I had never met before, only “knew” online, or I hadn’t seen since MMS Jazz in 2019. I’m sure I can’t recall every name, but I’m sure that many who couldn’t escape my yapping may take weeks to recover from the torture. I could kick myself for forgetting to take more photos.
Memories
Some moments that will stay with me for a long time:
The generosity and openness from every person I met
All the fantastic and funny conversations
Dinner with Sven and his wife
Dinner with Cameron, Beth, Matthew, Chris, and Phil
Multiple conversations with Matt Dewell, Robert Stein, Fabian, the guy standing next to Fabian who we discussed moving clusters, damn it, I can’t remember his name now, Wally Mead, Donna Ryan, Matt Zaske, Sven De Groote, James Karhan, Sandy, and many others who’s names I can’t recall (I’ll know your face and remember the topics as soon as I see you again)
Knowing that most of you likely had the same awesome conversations with these and many more.
Axe throwing (I suck at it)
The hammer and nail thing (I suck at that too)
How much I learned about things from the many conversations. From technology to house repair, investments, travel, gardening, and of course: a dozen NDA bomb drops from vendors
The closing session and raffle announcements
There’s just so many people and so much going on during that week, that it’s a challenge for me to recall details after just a few weeks, so please don’t be offended if I forgot to mention your name.
Wrapping Up
Overall, the attendance at MMS MOA this year was really good. I was told it was lower than pre-pandemic years (not a shock), but many of the sessions I attended were packed, and standing room only. The after-hour events were all fantastic, and another great opportunity to meet more people, share experiences and ideas, and have a lot of fun. And did I mention the beer?
At MMS Jazz (2019), I think I spent 80% of my time talking with speakers and 20% with attendees. This year, I flipped that around, and spent more time meeting attendees than speakers. I learned a lot from everyone I spoke with. If I offered you any advice, especially during the after parties, confirm everything before relying on it.
I’d like to give major kudos to Brian, Greg, Donnie and the rest of the MMS team, their spouses and families, as well as the sponsors and their teams and families.
Special thanks! to Wabasha brewery, and Bad Weather Brewing, for providing great quality products and service to a bunch of beer-deprived nerds! That cigar dude in the back was interesting and I learned a lot about Cuban cigars (I’ve still managed to make it this far without ever trying a cigar, how is that possible?).
Thanks to the hotel staff for somehow staying on top of the insanity (coffee, snacks, a/v equipment, climate controls, lighting, etc. etc.).
And a special thanks to Microsoft for making products that keep us all employed.
Takeaways
I realized that some folks were perplexed as to why I was wearing the infamous plaid jacket this year, and I get that too. MMS has a reputation for MVP-level speakers, and I’m obviously not an MVP. But I had a great time regardless, and I learned as much as anyone else from the other presenters.
If you are thinking of attending, I would emphatically say “yes! do it!“.
MMS is more than sitting in a room listening to a speaker. It’s kept intentionally small enough to encourage direct interaction between everyone, speakers and attendees alike. You’ll learn so much that your head will hurt the next morning. But, you’ll be ready to hit the ground running when you head back home.
The biggest takeaway for me was from mingling with others. You quickly realize how many others are working to overcome the same challenges you are. I hope you can make it to the next MMS!
Food CourtMe, Cameron and ChrisJohn and CameronNathan flying the planeI talked these two into a comaCamping session with John Marcum and Richard HicksScott and DonnieScott Corio on the rightWabasha tour, Phil at rightSir Johan!
5 Tips for Learning PowerShell
This could easily be “5 tips for learning anything”, but anyhow… So, I don’t consider myself an expert on anything really. I still think I’m a student at everything, which keeps me motivated to learn more. But as the awesome Mike Kanakos says, you don’t have to be an expert to share what you know with others who just starting out.
Start with a task you really want to automate. Something you are really familiar with. Start with something relatively simple
Try to break that task into smaller/simpler tasks first
Work on one of those tasks at a time
Watch the PowerShell Tool Making videos by Don Jones: part1, part2, and part3, then watch them again
Attend some PowerShell user group meet-ups (online or in person)
A good example comes from one of my clients. She wanted to build a script (or group of scripts) to keep a log folder clean by deleting files older than 180 days. The first step was to get a list (array) of files in the log folder, then use a filter to get only the files which are older than 180 days, then delete those files. Finally, she wanted to create a scheduled job to run the script daily. Once she mapped out those steps, she was able to focus on each one, and knock them out more easily.
Because it was a process she was already familiar with (from doing manual clean-ups), and she could break it down into separate pieces, it made the tasks easier to work on. She also watched the Don Jones toolmaking videos and praised the value they provided.
Short story: having some tools is one thing. Having a goal to build a picnic table helps associate the use of each tool to accomplish specific tasks.
Projects and Hobbies
Some things I’ve been playing with lately:
Running Android apps on Windows 11. I don’t know why. Just because
.NET Interactive Notebooks in Visual Studio Code. They’re really cool!
Logic Apps
Azure Automation Runbooks
Azure Resource Graph (mostly around policies, compliance and monitoring)
PowerShell lab work (applying what I learned at MMS)
Pressure washing. Why not?
Mountain biking. Where we don’t have any hills, let alone mountains
Getting outside again
Automation Checklist
During one of several UAT sessions with one of our clients for whom we build automation tools, we reviewed some of the process workflows. After my double-espresso with mushroom powder voodoo and 10 lb dose of vitamin B12, a thought came to me, actually, after the first thought about going to the bathroom, which was I should jot down some typical questions that help build an automation checklist. In this case, it’s related to user lifecycle processes (onboard, offboard, change):
Where is the request data coming from? What is the source of authority?
Will requests trigger the automation, or will it be scheduled (polling)?
What format will the request be provided?
Does each workflow get a unique request type?
Is the CSV, JSON or XML valid?
Are all the tags/elements/values populated?
Are all the values validated? How?
Do the names (first, last, middle, etc.) have diacritics or accents? (e.g. Latin, Unicode, etc.)
Do the ID numbers have the correct length and format? (think regex)
Is the email address valid? (regex again, maybe)
Does the proposed username (SamAccountName/UPN) exist in the target realm? (AD, AzureAD)
What request information is provided, and what must be derived?
What information will be derived from group-based keys (department, title, location, etc.)?
Is the proposed password provided in the XML?
Is the proposed password valid for the target realms?
What logging, alerting and reporting requirements are there?
Who needs to be alerts and when?
How will alerts be routed?
What privacy/sensitivity rules must be followed?
What resources will need to be accessed by service accounts or service principals? (File shares, REST endpoints, services, processes, WMI, registry keys, ServiceNow, Okta, Workday, ConfigMgr/MEM, etc.)
What permissions do the various service accounts or service principals need to each resource?
How will you handle interrupted workflows (resume after failures, etc.)?
What kinds of maintenance tasks need to be included?
What is the hand-off process (who will manage it after implementation)?
Who will “own” the process and related resources?
This is really only about half of the checklist. Thankfully, most of the technical aspects are covered by the automation platform itself, which I only support a small piece of (the rest is managed by a team of geniuses like this guy)
Don’t Forget About User Groups!
I posted a comment on Twitter about the value of user groups. Not just in-person, but online as well. Some of the replies included names and links I hadn’t heard about. Take a look at that thread and add more if you want.
If you’ve followed my blog for a few years, you probably know what that image above means. If not, well, it refers to moments when my blogging reaches a fork in the road. Get it? ha ha ha (cough cough). Okay, that’s pretty lame.
I’ve taken several sabbaticals in the past, usually from hitting writer’s block. Ironically, as soon as I would claim to be tossing in the towel, that’s when ideas came flooding in again. I don’t know if that will be the case this time, but I feel the need to pause for a bit. I just have too much going on with work, family, house stuff, and so on. I need to refocus and figure out what direction makes sense.
Most of my blogging was done during a period when nobody knew who I really was, from 2007 to 2015 that was kind of the point. My identity was out in 2016 and kind of spread since, which has made it more challenging to really share thoughts openly.
If you’ve ever been to an MMS event, you know that a major reason that sessions are not recorded is to foster an open discussion without fear of (employer) reprisal. I’ve always made sure to obfuscate names/places to avoid offending or embarrassing anyone. However, the kind of humor I’ve grown up with isn’t viewed the same today, and that makes it more stressful, and since I don’t earn any money from this blog, it’s hard to justify managing that added stress.
Part of me feels that just writing this is silly. It is about blogging and social media, after all, and not about curing cancer or ending poverty. I’m sure the planet will continue spinning.
(1) “My employer won’t pay for me to attend. What should I do?”
Quit! You don’t need that stinking employer anyway. Your future is worth more than they’re willing to invest. Find someone willing to invest in you, or do a bikini carwash.
(2) “I don’t like imaging computers. Why should I go?”
Silly nerd. There’s more to nerd life, and MMS, than imaging machines. Scripting. Automation. Cloud stuff. More Automation. Security stuff. Scripting Stuff. Stuff stuff. Even beer stuff. It’s all here! You’ll see people demonstrating some of the craziest nerd stuff ever. And some sessions on imaging too.
(3) “Where is Mall of America?”
It’s Mall that’s in America. More specifically, in the Minnesota area.”
(4) “Will any cool people be there?”
All the cool people will be there. I’m not sure how I get accepted, but my grandkids think I’m cool, so I’ll go with that. Check out the list of the coolest presenters here!
Microsoft made some significant announcements this week regarding MEM (mostly around Intune).
The new Remote Help feature is GA and cost is around $3.50 per user per month. Word has it that every user has to be licensed in order to use the service (not just administrators or help desk staff). Some are upset at the price, while others say it’s cheaper than the TeamViewer option.
I’m gonna party like it’s….
Buried deep inside the Windows 11 registry, you can still find nuggets of past treasure, buried like a dog hides a bone. Keys for “Skype”, “Netscape”, “Wordpad”, and “SkyDrive”, as well as “SoftGrid” and one of my personal favorite keys: HKLM:\SOFTWARE\Microsoft\Wow64\x86. Because WOW6432Node wasn’t good enough.
PowerShell Tune-Ups
Do you get frustrated with frequent errors/warnings when you run scripts? Quite often it’s from really simple things that can be addressed with very little change. Let’s take a look at a few examples.
Remove-AppxPackage -Package "fubar"
You can replace this with Remove-Item, Stop-Service, and so on. Basically, issuing a command to do something to a target that may not exist (or can’t be accessed). You’ll know because it throw more red on the screen than the last Rambo movie (towards the end when they invade his quiet, relaxing farm, and he goes on a butchering spree). Anyhow, a slightly cleaner approach would be to leverage the pipeline AND the ErrorAction parameter.
Now, this will make sure you can get the target item (i.e. AppxPackage named “fubar”), and only if it finds it, will it send it to Remove-AppxPackage to try to delete it. You may still get an error when trying to delete it (permissions, resource contention, etc.), so you could still wrap this in a try/catch block to handle that.
However…
This is all predicated on you not caring if the package/thing doesn’t exist. If you want to know that doesn’t exist (or is not accessible) that’s a different thing. There are quite a few ways to address this scenario, but one of the simplest is combining If/Else with ErrorAction.
If you’re still getting used to Microsoft Teams and conference calling, and maybe looking for some tips for making your conference calls more productive, fear not.
Remember to mute and unmute yourself every 2-3 minutes
When you want to stop sharing your screen, make sure to click the “leave” button instead
People love the echo effect. It reminds them of stadium movies like Rudy and The Replacements
Stop and ask “can you guys hear me?” every 30 seconds
Wait at least 3 minutes after sharing your screen before asking if anyone can see what you want them to see.
Ask half of the attendees to join using the web app, instead of the desktop app
Switch between tenants as often as possible. It’s like moving working loose a rusted bolt
When you dial in, give your name as “wanted fugitive“
At a random time during a conference call, unmute while yelling at your dog/spouse/kids/neighbor/dishwasher/TV/ or call out to Alexa, Google or Siri, then go back on mute
Point your camera at your mid-section.
Sit uncomfortably close to the camera.
When someone is sharing an emotional story, come off of mute while laughing hysterically, then go back on mute
More YouTube Surfing
I go in and out of channel surfing, but these are some of the ones I visit most often. My tastes are weird, like me, but don’t be hatin’. If you like any of them, great. If you don’t, that’s great too.
One of the clients I did some work for had this thing they did on Tuesdays or Wednesdays, I forget which, where they expected everyone to pronounce every word with an interim “A” as “ar” and a trailing “A” like, well, “aye”, the same way Sade pronounces her name (spoiler, it’s “shar-day”).
So “I made some coffee” turned into “I mar-day some coffee” (they actually said “I mar-day sar-may car-fay“), and so on. It was a lot of fun. Staff meetings were actually kind of fun. Let me know how this works in your staff meetings?
Twilight Zone
Speaking of consulting gigs… Back in 2015, I was working with a client in the food processing industry. Obviously I can’t say their name or provide too many specifics, but they worked with pork and name began with an “S”. Their naming convention for tech stuff (networks, routers, DNS zones, machines, service accounts, blah blah blah) was “SF”+whatever. Pretty boring, yes.
A month later, I was sent to a different (US) state to work with yet another food processing client, who does chicken. Well, they don’t really “do” chicken, because that would be weird. Or maybe not, since I’m old and can’t keep up with social trends. But this client worked with processing of chicken products, and their name also began with an “S”, and their naming convention was also “SF”+whatever, and almost exactly parallel in so many respects, that I thought maybe someone was playing a joke on me.
For example, their IT department office layout was identical. Same Steelcase model cubes, and desks, arranged very similar. The only difference was the shape of the buildings and parking lots. As I said, I really thought I was being pranked. But I wasn’t. These just happened to be similar, and happened to be lined up in my work queue. If you eat anything with chicken or pork, you’re probably enjoying one of their products. In fact, I learned how many things come from those two animals that are vital to other industries which I never expected. Medical supplies, cosmetics, fabrics and textiles, and so on. And now you know.
Questions? Comments? Abusive hateful thoughts? Kind and loving thoughts? Leave a comment below.
I hope you have an awesome weekend! Remember, making someone else smile, makes you smile too.
My search phrases over the past week are like an exercise in how to confuse psychoanalysts:
Japanese toilets
Chysanthemums
What happened to Bryan Ferry?
14 inch band saws
Outdoor solar lighting
250 technical searches from Azure, m365, to PowerShell, REST, Terraform and Kusto
Ikea store hours
Dog harnesses for a 100lbs dog
Definition of egalitarian
Definition of tantamount
who is Ron DeSanitize guy?
ViveTool no longer enables explorer tabs windows 11
What happened to Fabio?
Estimate shingle roofing materials for barn roof
why does my OnePlus 9 Pro suck so bad?
Is Apple a Slowly-Crashing Airplane?
After watching a few product reviews and the Apple March Event review by Marques Brownlee (highly recommended, even if you don’t use Apple products), I had some discussions with my son, who is a big Apple fan. Not so much because of the name itself, but because he works in the music production world, and that’s heavily tied to Apple products.
During that discussion, a vision popped into my head that seems like a very good metaphor/analogy for how Apple seems to be performing over the past few years: In war movies, especially those from WWII era, there were often air battle scenes where one pilot would be talking with another pilot on their team, and suddenly the other pilot wouldn’t respond. Then pilot one would look over and see pilot two’s plane slowly veering off towards the ground/ocean, obviously due to the pilot (two) being no longer living. That’s what Apple seems like to me.
It’s mostly incremental changes now. Not even incremental innovation. The innovation once famous from Apple, as a whole, seems to be gone. I wonder if that’s really true, and if so, is it really tied to Jobs being gone, or is there a bigger issue? But regardless, to me at least, Apple seems to be a pilotless plane, slowly heading for an eventual bad ending. I don’t even use Apple products, but to me that would be a very bad thing. Their innovation is what pushed the entire industry, in fact, multiple industries, to push harder than they ever would have otherwise. Desktops, laptops, tablets, TV interfaces, and of course: phones.
Cool Stuff and Events
MMS MOA 2022 is coming like a freight train! May 2 to 5 at Mall of America. Get your tickets now!
I’m doing a session on ConfigMgr health check automation using Azure Automation and 2 sessions where I’m co-presenting. If you’re coming to MMS MOA tap me on the shoulder and say hello!
If you have more than a few hybrid workers, and want a quick view in Log Analytics of how they’re doing, here’s a Kusto query that might help. Special thanks to MVP Cameron Fuller (@cfuller) for showing me how to use summarize. For me, this comes in handy with a particular tenant that seems to have issues where one of their hybrid workers doesn’t report in because their IT folks like to shut down VM’s without asking who uses them (thinking about cost savings only).
I was exploring some Date/Time calculations with PowerShell for a recent case I was working on. Just sharing a few snippets in case they’re helpful to anyone else. That’s not a typo below, “.value__” has 2 underscores at the end.
$StartOfWeek = (Get-Date).AddDays(-(Get-Date).DayOfWeek.value__)
$NextFriday = (Get-Date).Date.AddDays(5-(Get-Date).DayOfWeek.value__)
$DaysToXmas = (New-TimeSpan -Start (Get-Date) -End "12/25/$((Get-Date).Year)").Days
$DaysToIRS = (New-TimeSpan -Start (Get-Date) -End "4/15/$((Get-Date).Year)").Days
# Compare current time between two timezones using GridView selections
[array]$zones = Get-TimeZone -ListAvailable | Select Id,DisplayName | Out-GridView -Title "Select 2 Time Zones" -OutputMode Multiple
if ($zones.Count -eq 2) {
$tz1 = Get-TimeZone -Id $zones[0].Id
$tz2 = Get-TimeZone -Id $zones[1].Id
$offset1 = $tz1.BaseUtcOffset
$offset2 = $tz2.BaseUtcOffset
$utc = [datetime]::UtcNow
$time1 = (Get-Date $utc).AddHours($offset1.Hours)
$time2 = (Get-Date $utc).AddHours($offset2.Hours)
Write-Output "$(($zones[0].DisplayName).PadRight(42,'.')) $time1"
Write-Output "$(($zones[1].DisplayName).PadRight(42,'.')) $time2"
} else {
Write-Warning "you need to select 2 time zones"
}
Now I’ve got to get back to exam study. Until next time! (pardon the pun)
If you’re like me (I seriously hope not), and you (A) love Windows Terminal, and (B) forget to right-click to launch it with “Run as administrator” more times than you’d like to admit, here’s one trick:
Right-click on the new shortcut, and click Properties.
Click Advanced, check the “Run as administrator” box, click OK, click OK again
For a nice added touch, go back into the shortcut properties, and click Change Icon and choose a real icon, rather than using that Walmart dumpster box clearance icon. Shell32 still has some decent icons to choose from. Screen shots taken below while inhaling coffee that was brewed way too strong.
There. Now every time you launch that new shortcut, UAC will pop up and punch you right in the face. It’s going to be a good day!
PowerShell Split-OU
I’ve had to split OU paths for various reasons many times, and decided to make a little wrapper function for it. I’m sure someone else has done this, but my Google kung fu matrix master jedi skills came up short. Anyhow, if you know of a better version of this idea elsewhere, please let me know? Otherwise, I hope this is helpful:
UPDATE: Added -Suffix and condition checks for when $Path starts with “OU=”
Again, if there’s a better option out there in the world, let me know? I’d rather use that than invent another wheel.
Random Memories – Microsoft Ignite 2017 (Atlanta)
In October 2016, I hadn’t been with my employer a full year yet, when they decided to send about 12 of us to the Microsoft Ignite conference in Atlanta. I remember lots of walking, meeting dozens of new friends, insane beer and food consumption, and trying to comprehend Andreas explaining BranchCache and BITS to us at 8:00 AM in the morning.
I remember thinking “This guy is amazing! Why are we all so hung over?“. It seemed like everyone in attendance was struggling, but we were (are) really fortunate that his session was recorded. I learned a ton of information from that over the following week or two.
On the last night of the conference, six of us tried to form an ad hoc Entourage-ish gang, and go adventure-seeking. Most of this “gang” were either old, or out of shape, okay both, so the mission ran out of steam after an hour. The guys pealed off gradually, and headed back to their hotels to crash. But for some reason, I still had a lot of energy at midnight, so I went on a walkaboutthrough downtown Atlanta.
I didn’t realize until later that I had covered an area roughly from the GWCC to Central Park, and from Five Points to Tech Square. When I traveled more often, my favorite thing was to walk around and explore on foot, if possible.
Anyhow, I noticed how many of the North/South cross streets were poorly lit, like between the Aquarium and Central Park. I would discover later on that these poorly-lit streets had the highest rate of violent crime, particularly against idiots like me. Anyhow, each time I would emerge onto a street with lighting, I noticed more and more strange zombies slowly following me. Eventually, I out-walked most of them. As it turns out, heroin isn’t a performance-enhancing drug.
I was still over-dressed and toting a “Microsoft” backpack with a ton of lanyards and badges and buttons, look like a nerd version of Mardi Gras. The message I probably gave off: “Please beat me and rob me!“.
Sometime around 2 AM, I ended up talking to an elderly homeless guy (probably in his 40’s but looked like in his 70’s or 80’s). I don’t remember the details, but we covered topics from the concept of money to failed family relationships and weather. I offered him a vendor t-shirt from my backpack. Soon, another person approached, and I handed out another t-shirt. Then another, and so on.
I figured, well, I’m about to be murdered on the streets of Atlanta, at least I can distribute some good will and free advertisement.
The next day I headed back home. But, while standing in line waiting to be cavity-searched by TSA, I kept thinking of what it might look like driving around that area in the morning. Unconscious homeless people strewn about on park benches, sidewalks, alleys, wearing brightly colored vendor shirts and ball caps.
From the poorest laborers in the sweatshops of China and Vietnam, through the distribution channels of EU and US, to the booths on the expo floor at the Microsoft Ignite conference, ultimately onto the bodies of the poorest people of Atlanta. Hopefully, I was a value-add step in the process.
Pest Control Knocking
I may have found a bug in Azure AD audit logging. May have. Maybe. Possibly. Here’s the Twitter thread. Hopefully it can be fixed soon and with little effort. Basically, when modifying an Azure AD user to change their “usagelocation” property, the audit log doesn’t show any details. It just shows “Member”, which is kind of odd. What it should show (I think) are the old and new values, and who made the change. Or I’m completely wrong and ignorant. Stay tuned.
Controversial Thoughts: CI/CD
CI/CD, or Continuous Integration / Continuous Delivery (or “Deployment”, but feel free to pick your own “D” meaning), went from being the “buzz” to becoming an accepted daily thing. Many developers I’ve spoken with seem to believe it emerged around 2018, but is that really accurate? By the way, this isn’t really the focus of what I’m diving into here. More of a side note.
The CI/CD concept seems rational: release changes (implied: improvements) as they’re ready, not based on a periodic calendar table, as had been the norm for decades. But the practice of CI/CD dates much farther back, possibly to the beginnings of software development, and especially with regards to in-house development.
If you think back to many “in-house” projects from the 1980’s to even now, there was a lot of releasing going on that didn’t fall into a yearly/quarterly/monthly cadence. This is particularly more common in the early phases of a project, when feature changes and bug fixes more frequent.
Releasing things to the public, especially when a contract of some sort is involved, incurs a more rigorous set of controls. This is even more relevant when it comes to larger vendors. So, as far as I can tell, the idea of CI/CD is really only “new” to commercial and government/defense software; it’s been the “norm” for in-house projects since Grace Hopper gave birth to most of what most of us take for granted now.
I believe that the biggest problem with CI/CD is the implied “improvement” aspect. There seems to be a collective confusion about the definition of words today, and it applies to this word as well. According to Merriam-Webster’s dictionary, it means “an instance of such improvement : something that enhances value or excellence” (2b). I would argue that patching a broken feature, fixing a “bug”, is not an improvement, but this is obviously semantics.
If you pay for a new house, after being sold on the presentation which clearly shows features you wanted, but then find out after moving in that many are not installed or finished, do you label the finishing of those incomplete features an “improvement”? Maybe. But when you’re in debt to the mortgager for $XXX,000 USD, I doubt you’re in a mood to call that as such.
“See? We improved your house by installing the front door you were expecting!”
With CI/CD, the term improvement appears to have a subtle new meaning. For example, which of these is more of an “improvement”?
A. Finishing the stated/promised capabilities of a recently-added feature.
B. Adding another new feature, knowing it will be incomplete for some time.
Many would argue A has a higher value. But vendors are influenced by budgets, which are influenced by revenue, which is influenced by sales, which is heavily influenced by impressing customers. They would argue B has a higher value.
For many technology vendors up until around 2010, the customers were often technical. Convincing them to buy new products meant selling them on capabilities being ready for production. Since then, the customer focus has shifted more to the decision-makers, or purchasers. Selling them on new products leans more on promised features than proving their immediate readiness. It’s more about vision, direction, strategy, and less on the short-term.
The net result is an endless gyration of new features which remain incomplete for longer than expected, while newer features are continuously added, which are also incomplete. Some of these new features remain incomplete for months or years. There are many examples of this, but you probably can think of a few.
But do I think that CI/CD is bad? No. The concept of CI/CD makes sense to me, but the practice of it isn’t what I’d hoped for. Software makes it generally less of a challenge to complete features after release than can be done with physical products. So there’s less concern/care about releasing unfinished software products and services than there was a few decades ago. We’ve traded speed for fit-and-finish.
In short: I think CI/CD, as practiced, means: Continuously Incomplete / Continuously Disrupting. But I also think it’s here to stay for a long time.



















































































You must be logged in to post a comment.